
Machine Learning avanzado
Conexión con productores agropecuarios locales
Modelos propios basados en miles de horas de entrenamiento local
Combinamos miles imágenes satelitales de 10x10m y datos a campos
De lo global a lo local:
Modelos de machine learning calibrados regionalmente para decisiones más sustentables, transparentes y trazables.
Machine Learning avanzado
Conexión con productores agropecuarios locales
Modelos propios basados en miles de horas de entrenamiento local
Combinamos miles imágenes satelitales de 10x10m y datos a campos
Los datos satelitales de deforestación global, como los de Hansen/Global Forest Watch, son útiles para detectar tendencias generales, pero no fueron diseñados para decisiones regulatorias o comerciales.
Sus propios creadores advierten:
“Estos mapas no deben usarse para regulaciones, certificaciones o sanciones sin validación local” (Hansen et al., 2022; GFW FAQ).
El problema:
❌ No distinguen entre deforestación, degradación o estrés hídrico en ecosistemas secos (ej. el Gran Chaco).
❌ Pueden tener errores del 20-30%, generando sanciones injustas o validando áreas erróneas.
Nuestra ventaja: Machine Learning calibrado para la realidad local
✔️ Modelos entrenados con datos específicos de cada bioma (2020-2025).
✔️ Precisión superior (F1 > 0.95) en detección de deforestación real.
✔️ Validación en campo y análisis satelital detallado para decisiones confiables.
Para garantizar transparencia y cumplimiento normativo, es clave trabajar con datos confiables que soporten auditorías serias.
Recomendación General: Balance entre Precisión y Operatividad
Al analizar las métricas para distintos tamaños de grillas (100 mil a 3 millones de hectáreas), se observa que:
Con diámetros pequeños (20 km): Se logra precisión altísima (F1 > 0.95), ), pero gestionar tantas zonas requeriría un desarrollo de varios meses.
Con diámetros grandes (160‑200 km): Se reducen las zonas a procesar y se agiliza el análisis, aunque algunas coberturas como Soja y Pastizal pierden algo de precisión (F1 ≈ 0.88‑0.90).
Balance recomendado:
Conclusión: Para optimizar eficiencia y precisión, se recomienda trabajar con grillas de 3 millones de ha (200 km de diámetro). Si el enfoque prioriza máxima precisión sobre operatividad, bajar a 60 km puede ser viable, pero a costa de más tiempo y recursos.
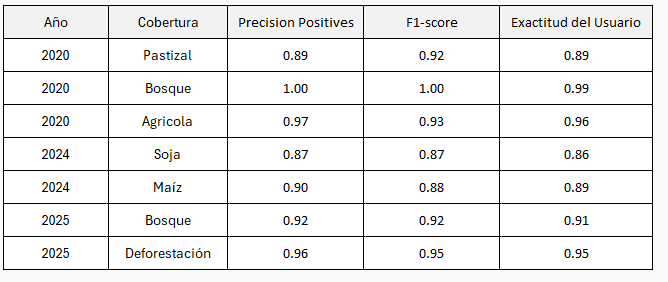
A partir de la matriz de confusión (TP, FN, FP, TN) se derivan indicadores esenciales para evaluar el desempeño: la Exactitud del Productor y la Exactitud del Usuario.
Para no sobrecargar la visualización, elegimos centrarnos en tres indicadores clave:
Definiciones adicionales:
TP (True Positives): Casos de la clase Cobertura que fueron correctamente identificados.
FP (False Positives): Casos que no pertenecen a la clase Cobertura pero se clasificaron erróneamente como positivos.
FN (False Negatives): Casos de la clase Cobertura que fueron clasificados erróneamente como negativos.
Precision_Positives: Mide qué proporción de los píxeles clasificados como una clase realmente pertenecen a ella.
Recall_Positive Rate: Mide cuántos píxeles de la clase real fueron correctamente identificados.
F1-score: Métrica equilibrada entre precisión y recall, útil cuando hay un desequilibrio de clases.
Exactitud_Productor: Se calcula como TP / (TP + FN) * 100, representando la confiabilidad desde la perspectiva del productor.
Exactitud_Usuario: Se calcula como TP / (TP + FP) * 100, representando la confiabilidad desde la perspectiva del usuario.